使用 chatGLM 官方示例做微调
-
- 环境
Linux 云平台 autodl 花费 10元左右
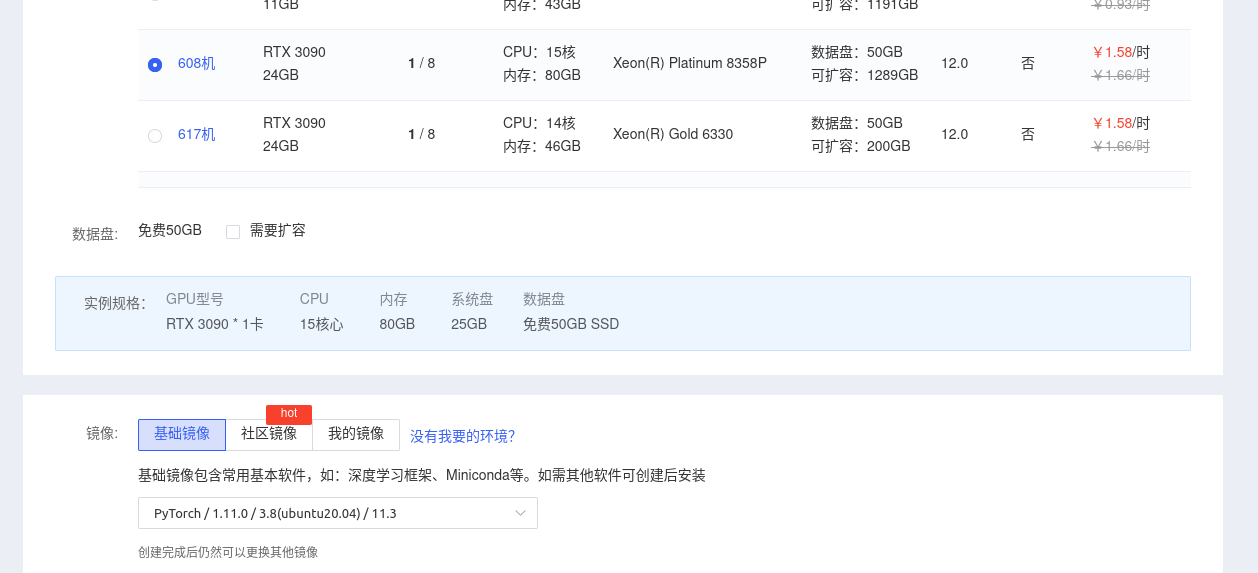
配置是24G的显存,3090显卡。
为什么选择这款配置?因为我在本机6G 显卡折腾好久没有成功。 用的 6b-int4 版本,网上都说可以成功。折腾我好久。所以干脆用云24G的实验了。
- 下载源代码
git clone https://github.com/THUDM/ChatGLM-6B cd ChatGLM-6B pip3 install -r requirements.txt- 进入微调
cd ptuning pip3 install rouge_chinese nltk jieba datasets- 下载 需要例子数据
wget -O AdvertiseGen.tar.gz https://cloud.tsinghua.edu.cn/f/b3f119a008264b1cabd1/?dl=1 tar xvf AdvertiseGen.tar.gz下载后需要展开。
- 修改 源文件
为什么要修改,如果不修改 总是 按照多gpu处理,我没有多gpu,并且即使是多GPU,也需要修改代码
这里有讨论
https://github.com/THUDM/ChatGLM-6B/issues/1169
我的方法如下:
ptuning/main.py 59 60 training_args.local_rank = -1 61 增加上面这句- 开始 工作
P-Tuning v2
bash train.sh- 如果你需要 微调
24G 显存不够
需要再修改
增加 Lora
pip3 install deepspeed vim ds_train_finetune.sh --per_device_train_batch_size 4 \ 修改为1 --num_gpus=4 修改为1vim main.py
头部 增加 : from peft import get_peft_model, LoraConfig, TaskType 第 136行 增加 下面的代码: peft_config = LoraConfig( task_type=TaskType.CAUSAL_LM, inference_mode=False, r=finetune_args.lora_rank, lora_alpha=32, lora_dropout=0.1, target_modules=["query_key_value"], ) model = get_peft_model(model, peft_config)以上可以 在24G显存测试通过。
- 环境