一步一步做微调 Finetune
-
OpenAI chatGPT 对外公布可以微调以后。 Finetune 技术就非常火爆。
1、什么是微调?
对于普通开发者来说,微调就是把自己的个性化内容加入到已有的成熟的大模型里面。
让大模型回答自己的个性化内容。
他属于 迁移学习的部分, 他是在已经成熟的模型上增加定制化的内容。2、为什么需要微调?
因为大部分开发者没有自己做模型的能力,因为很多开发者无法获取大量数据,并且专业的技术都参数也不太了解。
所以大部分人如果需要将自己专业领域的数据 加到大模型里,就会选择使用微调。3、如何微调?
# 加载预训练的VGG16网络 model = models.vgg16(pretrained=True) # 修改最后一层为二分类输出 model.classifier[-1] = nn.Linear(model.classifier[-1].in_features, 2) # 冻结除最后一层外的所有参数 for param in model.parameters(): param.requires_grad = False for param in model.classifier[-1].parameters(): param.requires_grad = True这个代码的例子,就是 获取一个成熟的模型vgg16, 但是修改了最后一层。
微调的方法就是 将其他层参数冻结,仅仅 修改最后一层参数。4、大模型微调
大模型的微调 流行的做法使用 peft的lora。
lora 为什么能微调很多大模型?只要这些模型包含全连接层或者类似的线性变换层。例如,chatglm、chatglm2、Alpaca 等都是基于 transformer 结构的语言模型,它们都包含多头注意力层和前馈网络层,这些层都可以使用 peft lora 进行微调。具体来说,可以在每个注意力层或者前馈网络层的权重矩阵旁边增加一个低秩适配器,由两个矩阵相乘组成,然后将适配器的输出与原始权重矩阵的输出相加得到最终输出。
5、peft 官方例子
from transformers import AutoModelForSeq2SeqLM from peft import get_peft_config, get_peft_model, LoraConfig, TaskType model_name_or_path = "bigscience/mt0-large" tokenizer_name_or_path = "bigscience/mt0-large" peft_config = LoraConfig( task_type=TaskType.SEQ_2_SEQ_LM, inference_mode=False, r=8, lora_alpha=32, lora_dropout=0.1 ) model = AutoModelForSeq2SeqLM.from_pretrained(model_name_or_path) model = get_peft_model(model, peft_config) model.print_trainable_parameters() # output: trainable params: 2359296 || all params: 1231940608 || trainable%: 0.19151053100118282内存空间展示
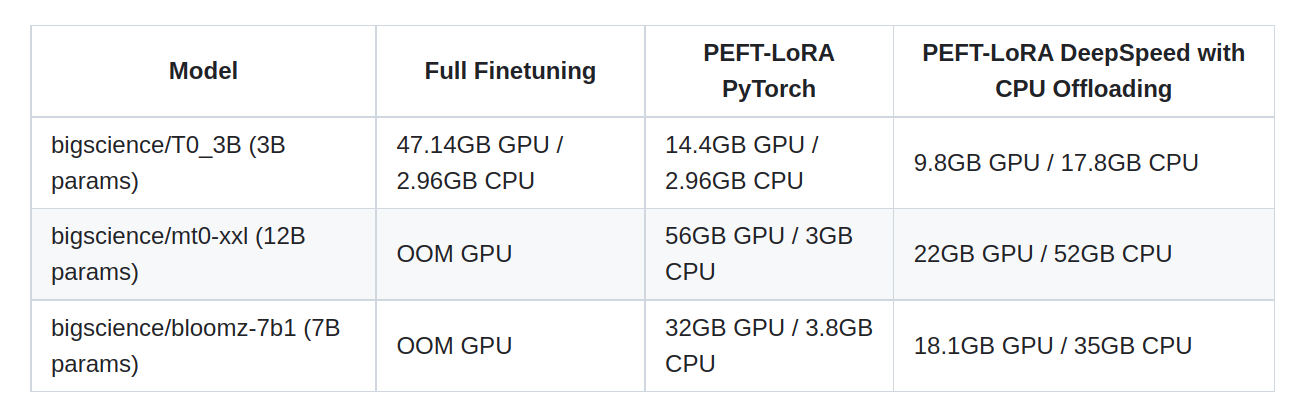
使用 accelerator 和deepspeed
减少GPU空间
model, optimizer, train_dataloader, eval_dataloader = accelerator.prepare(model, optimizer, train_dataloader, eval_dataloader)